As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation.
In response to these challenges, we introduce ![]() OmniBench, a self-generating, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition.
OmniBench, a self-generating, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition.
To evaluate the diverse capabilities of virtual agents on the graph, we further present ![]() OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities.
OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities.
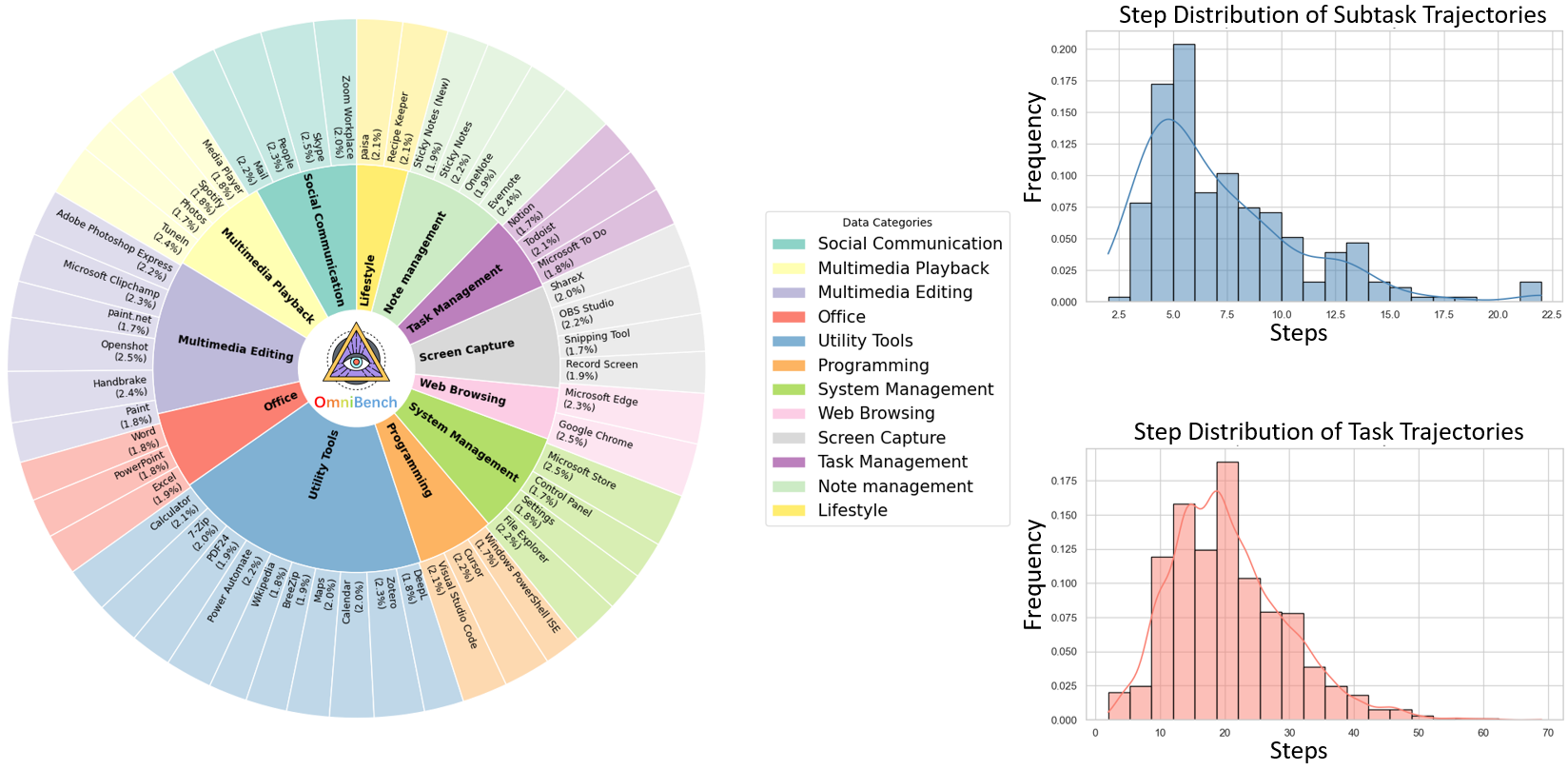
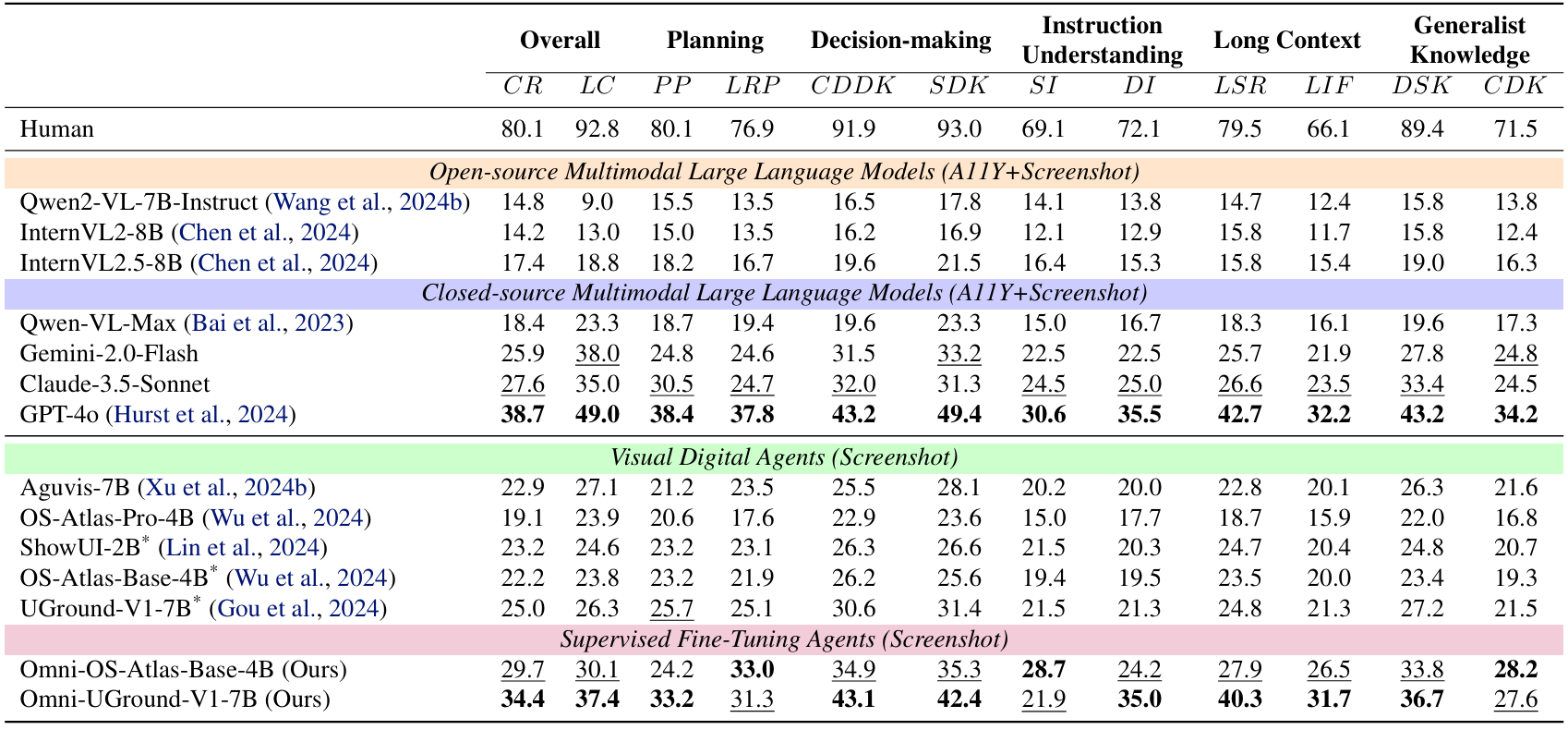
Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements.
To cost-effectively construct diverse task scenarios with complexity at multiple granularities for comprehensive agent evaluation, we propose a novel self-generating, graph-based benchmark, ![]() OmniBench. It dynamically synthesizes tasks with controllable complexity based on a bottom-up pipeline.
OmniBench. It dynamically synthesizes tasks with controllable complexity based on a bottom-up pipeline.
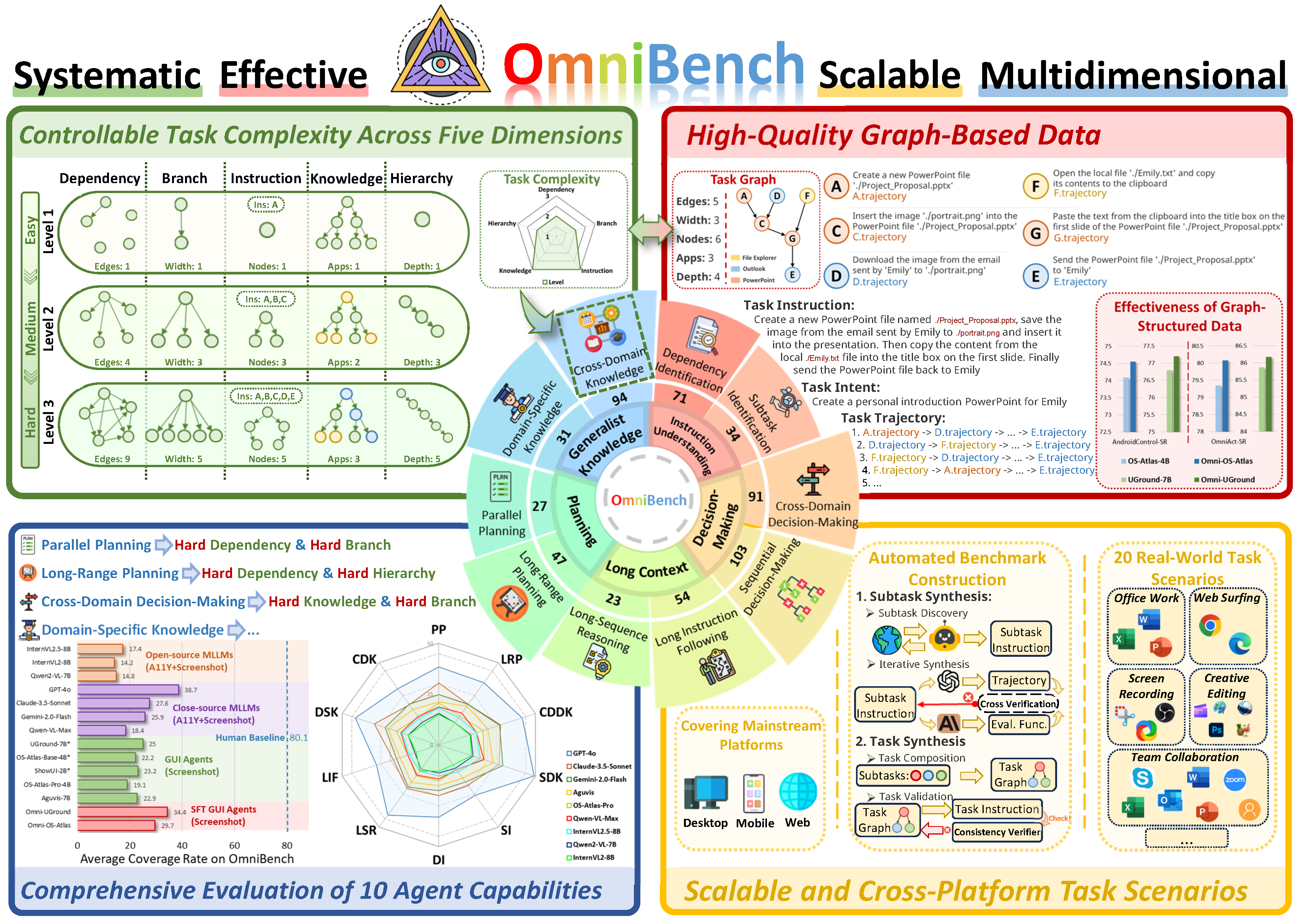
![]() OmniBench spans five fundamental types of task complexity to construct 10 evaluation dimensions (see the main figure). Test tasks across these dimensions are categorized based on combinations of complexity types. For example, a long-range planning test task typically exhibits higher dependency complexity and hierarchical complexity.
OmniBench spans five fundamental types of task complexity to construct 10 evaluation dimensions (see the main figure). Test tasks across these dimensions are categorized based on combinations of complexity types. For example, a long-range planning test task typically exhibits higher dependency complexity and hierarchical complexity.
We designed a bottom-up automated pipeline to synthesize tasks with controllable complexity. This pipeline consists of four processes:
(1) Subtask Discovery: First, we synthesize a series of simple subtask instructions from the explorable environment.
(2) Subtask Synthesis: Then, we iteratively synthesize subtask trajectories and evaluation functions.
(3) Task Composition: Next, the subtasks are combined into a task bottom-up.
(4) Task Validation: Finally, we validate the semantics of the tasks.
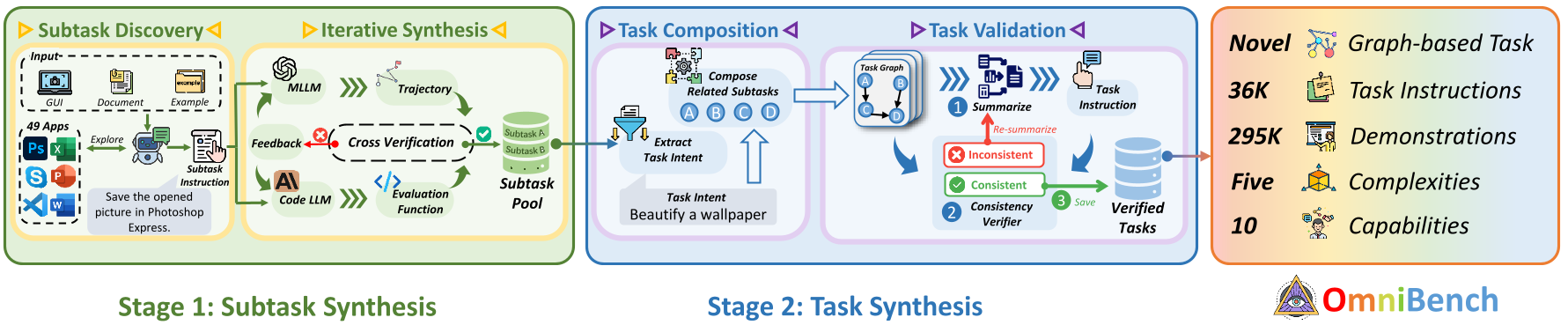
Bottom-up task synthesis pipeline of ![]() OmniBench.
OmniBench.
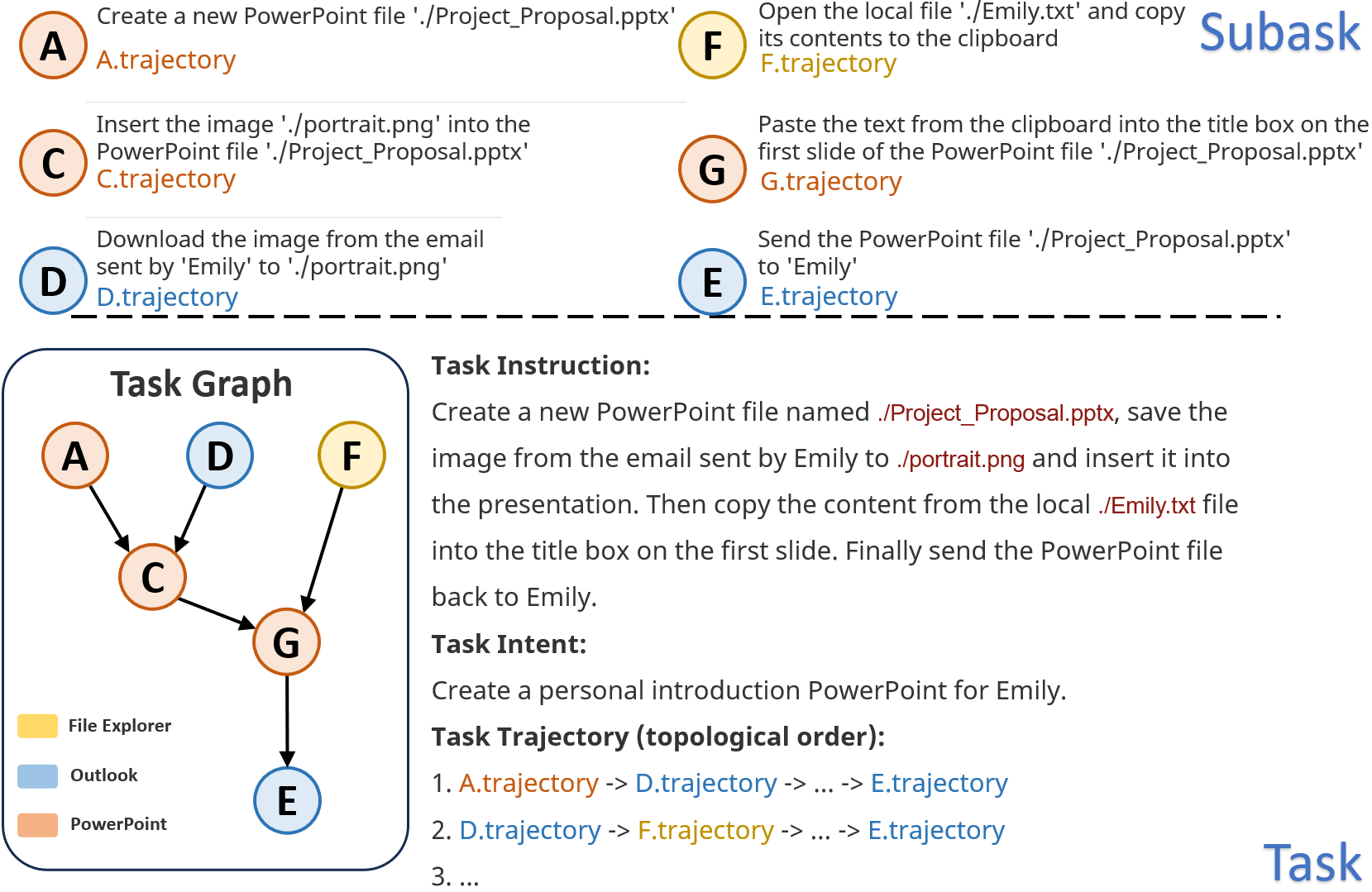
Task Instruction: Create a new PowerPoint file named ./Project_Proposal.pptx, save the image from the email sent by Emily to ./portrait.png and insert it into the presentation. Then copy the content from the local ./Emily.txt file into the title box on the first slide. Finally send the PowerPoint file back to Emily
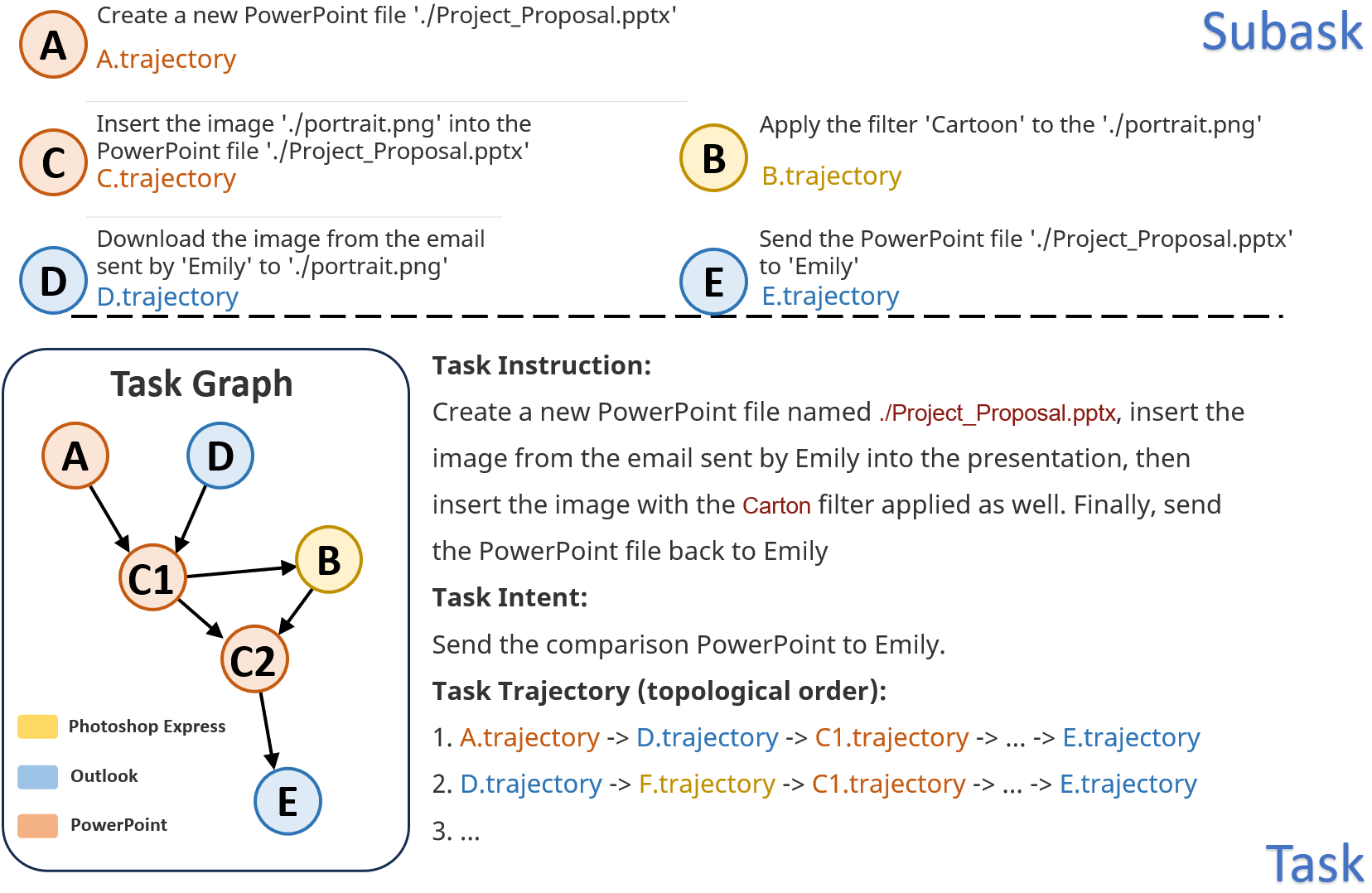
Task Instruction: Create a new PowerPoint file named ./Project_Proposal.pptx, insert the image from the email sent by Emily into the presentation, then insert the image with the Carton filter applied as well. Finally, send the PowerPoint file back to Emily
We propose a graph-based multidimensional evaluation framework, ![]() OmniEval. In contrast to previous coarse-grained evaluation methods, we introduce a graph-based evaluator that applies subtask-level evaluation functions in
OmniEval. In contrast to previous coarse-grained evaluation methods, we introduce a graph-based evaluator that applies subtask-level evaluation functions in ![]() OmniBench.
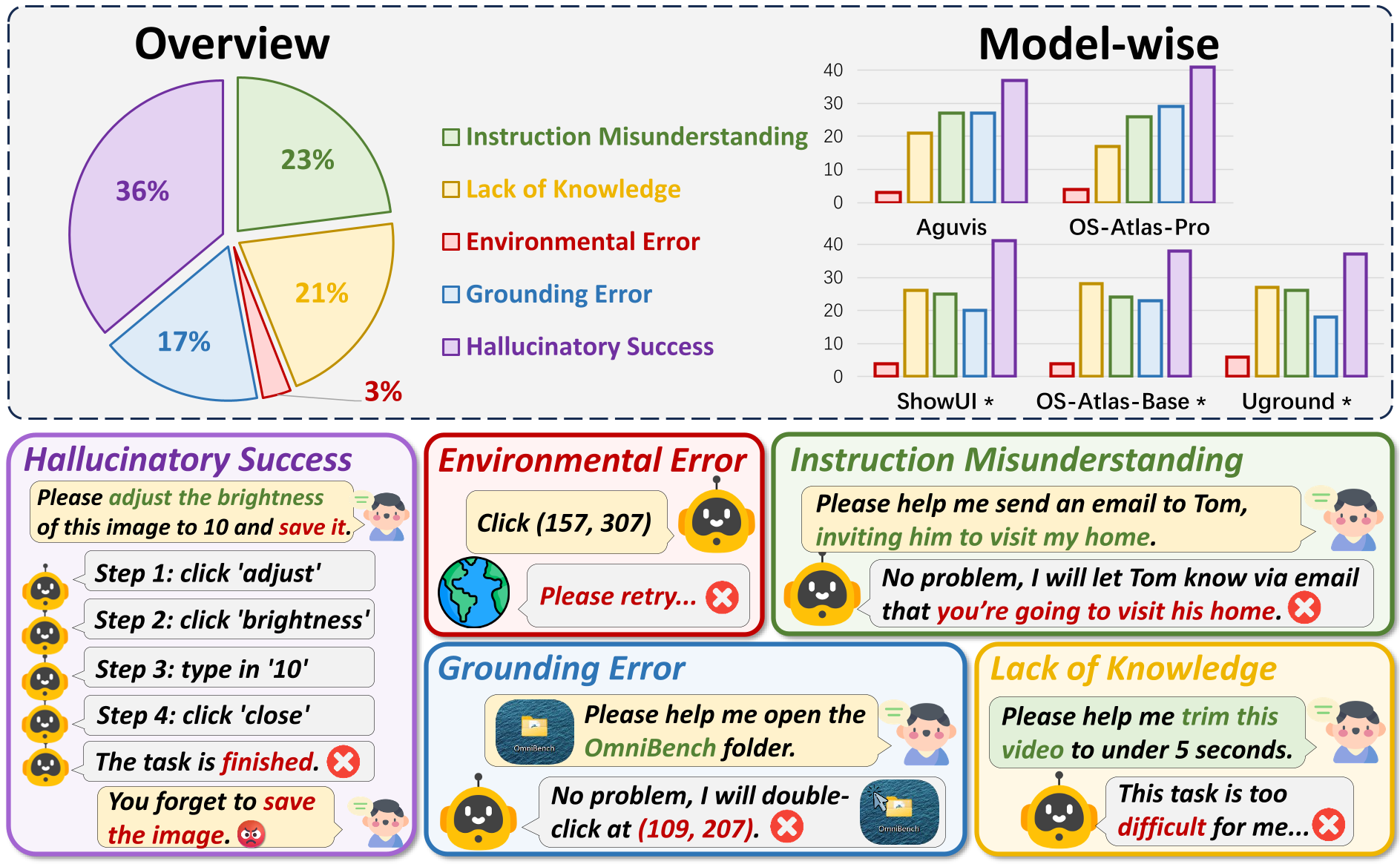
Specifically, we design two novel fine-grained metrics to evaluate agents' performance on graph-structured tasks and their alignment with human logic.
Based on
OmniBench.
Specifically, we design two novel fine-grained metrics to evaluate agents' performance on graph-structured tasks and their alignment with human logic.
Based on ![]() OmniBench, we comprehensively evaluate 12 virtual agents, including both open-source and proprietary models, across all 10 capability dimensions as shown in the main figure, fully revealing the capability boundaries and providing concrete directions for future improvement.
OmniBench, we comprehensively evaluate 12 virtual agents, including both open-source and proprietary models, across all 10 capability dimensions as shown in the main figure, fully revealing the capability boundaries and providing concrete directions for future improvement.
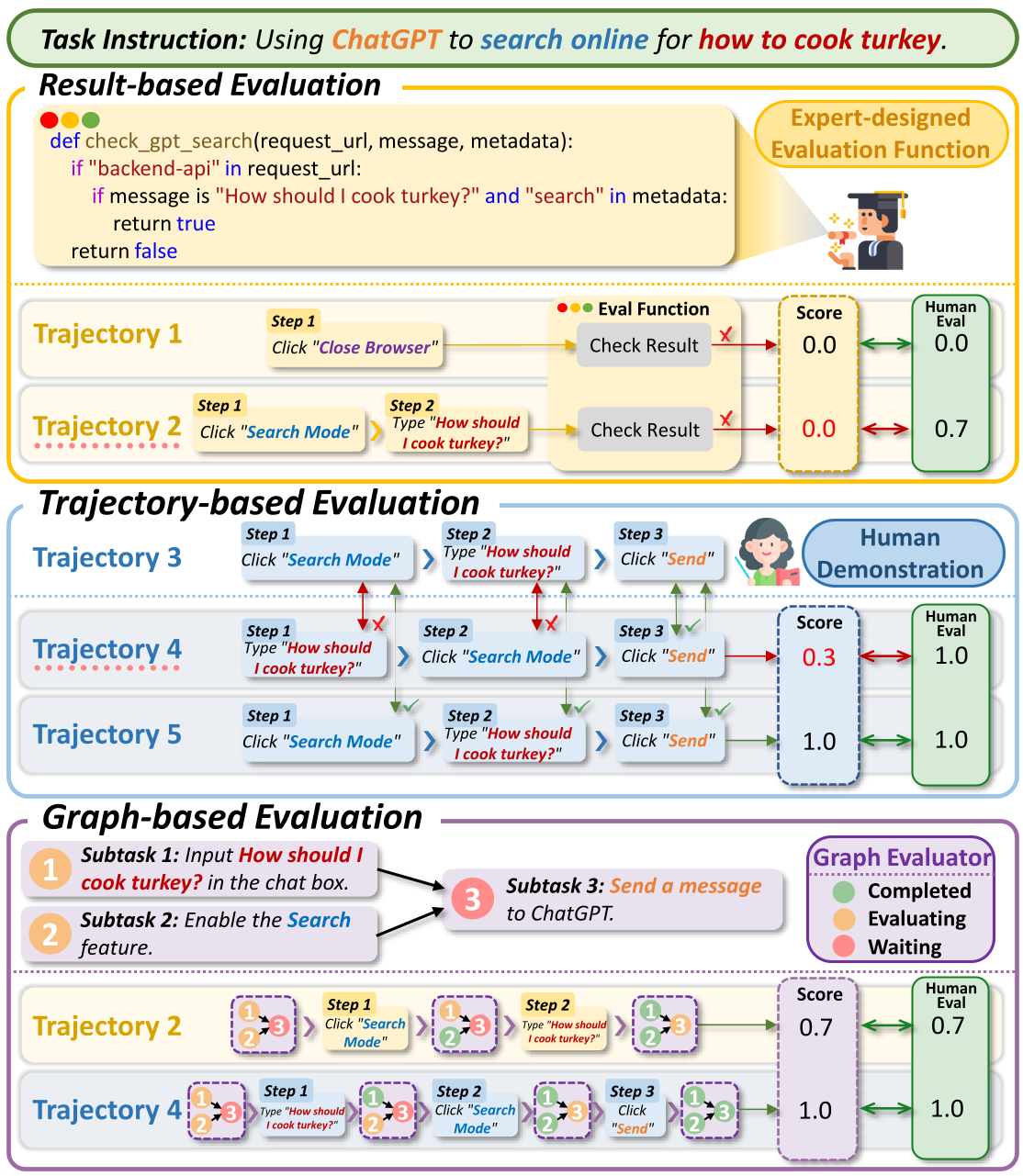
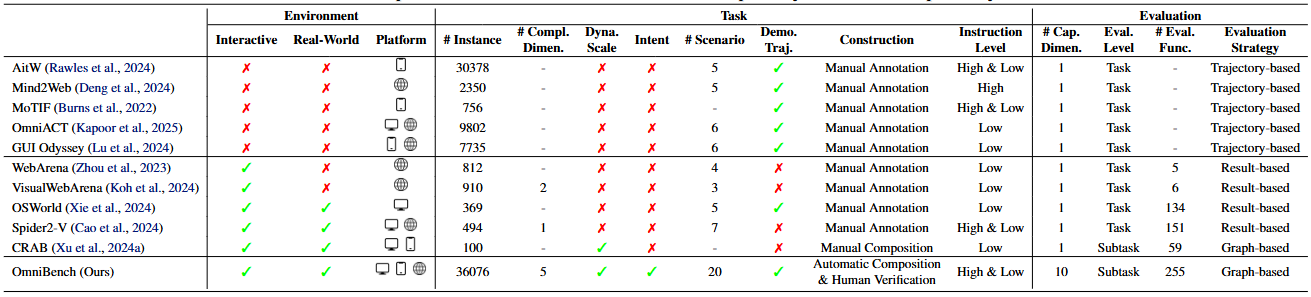
Comparison of mainstream virtual agent evaluation strategies with the evaluation strategy we propose.
@article{bu2025limits,
title={What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities},
author={Bu, Wendong and Wu, Yang and Yu, Qifan and Gao, Minghe and Miao, Bingchen and Zhang, Zhenkui and Pan, Kaihang and Li, Yunfei and Li, Mengze and Ji, Wei and others},
journal={arXiv preprint arXiv:2506.08933},
year={2025}
}